Scaling Knowledge Management and Modeling Practices Across Process Formats
Knowledge Management: the Enabler of QbD
The introduction of Quality by Design (QbD) fundamentally changed expectations around how biopharmaceutical processes should be developed, understood, and controlled. Rather than relying on observed empirical success, organizations are expected to design quality into the process, which required a deep understanding of the underlying process dynamics and factors that contributed to quality outcomes.
This shift has a direct consequence: QbD required the systematic collection, organization, and use of large volumes of process information. Material attributes, process descriptions, development studies, experimental data, models, control strategies, and ongoing performance data must all be available, collected, contextualized, interpreted, and comprehensively managed.
QbD, therefore, is only as effective as the knowledge management (KM) framework that supports it, which aims to convert these data into usable, actionable information and insight that supports decision-making across the process lifecycle. Where the complex dynamics and interdependencies within a bioproduction system are beyond human computation, models have stepped in to interpret this data. Despite being a key source of knowledge, modeling remains a niche, highly specialized activity with limited integration into core development tasks and knowledge management practices.

Models the Cornerstone of Knowledge Management
Within an effective KM framework, process models play a central role. Properly implemented, models enable three key functions:
Knowledge Containers: Models formally encode process/system behavior, capturing relationships between inputs, states, and outputs, and store them in a structured, dynamic form ready for use.
Generators of Insight (& Guidance): Through simulation, “what-if” analysis, optimization, and risk-based decision support, models actively create new insight beyond what is directly observed in experimental data. When configured appropriately, models can provide prescriptive decision support.
Formal Knowledge Assets: Models become governed, versioned digital assets, managed like code or documentation, that evolve and mature with the process. They become a key asset during tech transfer
Seen through this lens, models are not merely analytical tools. They are key KM assets that transform raw data into information and insight, enabling organizations to move up the classic Data–Information–Knowledge–Wisdom pyramid.
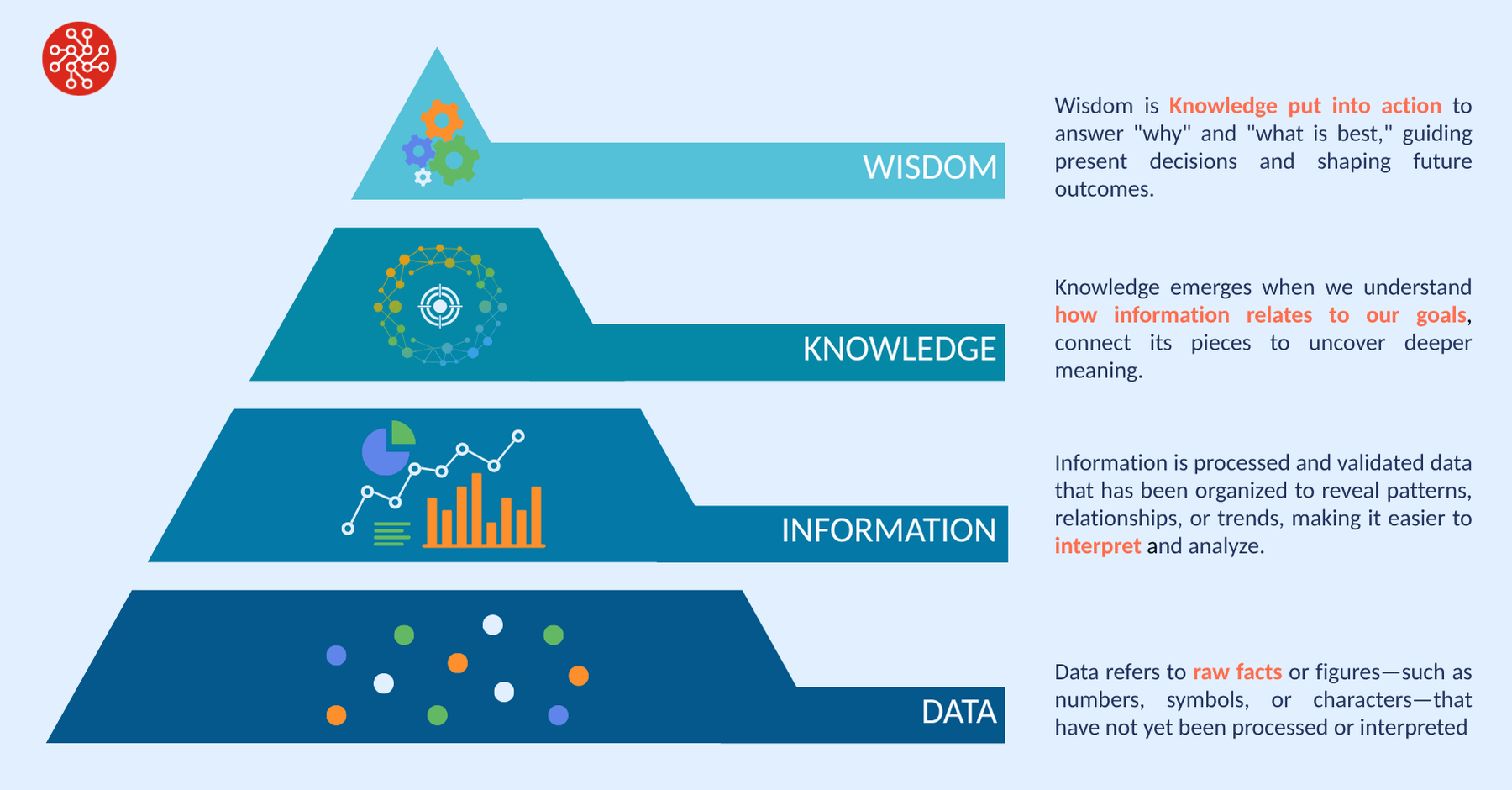
Why Modeling Must Become an Institutional Capability
In many organizations, modeling is still treated as a siloed activity performed by a small group of specialists to answer narrow, often short-term questions. This approach introduces several structural risks:
Knowledge Concentration: Organizational reliance on a small number of subject-matter experts creates multiple single points of failure and increases the risk of permanent knowledge loss.
The Scientist-Data Gap: Failure to bridge the divide between data generators (process scientists) and data analysts (data scientists/modelers) often leads to information loss or misinterpretation.
Siloed Standards: Lack of consistency among human talent, models, approaches, or outputs across projects, sites, organizations, or modalities leads to inconsistent operational performance and outcomes.
The Truth Conflict: Generating independent, non-versioned models creates confusion over which model represents the current “truth”. When in doubt, work is often rerun.
Model Drift: Models are rarely maintained post-project, leading to technical obsolescence and “drift“ (where model predictions lose accuracy as the physical system evolves).
Sunk Cost & Knowledge: Knowledge encoded in models remains isolated to projects, modalities, development cycle and process teams, and subsequently becomes difficult to transfer. The return experimental effort is lost.
Manual Friction: Weak integration with ELNs, LIMS, SCADA, or data historians leads to manual data entry and increased risk of human error.
As a result, organizations accumulate siloed datasets and models but fail to institutionalize learning.
From Siloed Activity to the Backbone of Process Development
Alternatively, process modeling holds the potential to function as a core development activity underpinned by clear standards, frameworks, and methods. The foundations of such an approach are:
Centralized Model Libraries: A repository of models (including hybrid, mechanistic, or data-driven) adapted for specific modalities and unit operations, available for organisational use. Models are managed centrally and used/trained locally.
Model versioning and traceability: The process model is treated as a core KM asset that is developed and managed with the process, with robust model versioning and governance, and explicit linkage to products, cell lines, development cycle, process operations, process data, and generated knowledge.
Structured Digital Development Framework: A consistent methodology that supports optimal model usage across diverse development activities towards defined process goals. This crucial component forms the operation best practice that transforms modeling from a task to an orchestrator of development activities.
Digital Development Framework and Learning Loops
DataHow, a leader in the development of bioprocess hybrid models, has formally developed this concept under their Digital Development Framework. Iterative learning loops systematically connect data (historical or ongoing experimental campaigns), modeling, knowledge generation, and recommended actions.
This framework is brought to life in DataHow’s process intelligence platform DataHowLab.
Digital Development Framework

Leverage Existing Knowledge First: Where prior knowledge exists (across products or scales), the systematic use of historical data via model-based transfer learning is incorporated to reduce the need for new experimental data.
Model-based Experimental Design: Design the right next experiments, informed by existing knowledge and explicit process objectives, to guide efficient, effective development.
Seamless Data Flows from the WetLab: Consistent data structures and direct integration with ELNs, LIMS, SCADA systems, and data historians.
Standardized Workflows for Specialised Tasks: Guided model training, evaluation, and validation, supported by workflows that allow non-experts drive the activity.
Model-based Insights & Next Steps: Structured generation and assessment of model-based insights with clear outputs and prescriptive actions.
Cross-Modal Consistency: One Framework, Many Systems
A key advantage of this framework is that it can be replicated across modalities. After adapting the underlying models to fit the different characteristics, goals, and constraints of the respective system (e.g., cell culture, cultivation, chromatograph) the underlying learning workflow remains the same.

DataHow has made these adaptations within DataHowLab, so that multiple formats are supported under a unifying approach. The technology, framework, and intelligence platform have been developed over nearly a decade of close collaboration with industry, and validated success, with many leading industry players already operationalizing the software at scale.
The Benefits of Organizational Standardization
For small organizations, reliance on standardized frameworks and repeatable workflows provides a cost-efficient operational blueprint that reduces dependence on individual experts.
For large organizations, the benefits are even more pronounced:
- Consistent inputs and outputs of process knowledge and insights across sites and programs
- Change management that scales: implement methodological improvements once and replicate across multiple sites
- A modeling platform that acts as a knowledge integrator, enabling reuse, transfer learning, and institutional memory
Conclusion
Quality by Design sets clear expectations for process understanding, but it is the underlying knowledge management framework and workflows that determines whether those expectations can be met sustainably and at scale. Treating process models as governed, living knowledge assets at the heart of bioprocess development, rather than isolated analytical tools, enables organizations to systematically convert data into insight, and insight into action.
By embedding modeling into a consistent, cross-modal learning process, organizations can institutionalize knowledge, reduce dependence on individual experts, and maintain methodological continuity even as products, technologies, and biological systems evolve. A systematic, robust approach to model-based bioprocessing supports faster, more confident decisions across development and manufacturing while preserving and compounding organizational learning over time.