The Impact of Hybrid Models on Bioprocess Development
Bioprocess development presents a unique challenge for data science
Bioprocess development is a complex, time-consuming, and expensive process requiring numerous wet-lab experiments to understand, optimize and characterize process behavior. For years, statistics have been used to support process understanding – with some success. Mechanistic models could potentially provide more process understanding, but they have limitations when trying to understand rather unusual factors. Machine learning models could overcome this limitation, but they require high volumes of data before they can be used with confidence – something which is in short supply during process development.
Hybrid models, which combine the two approaches, are a perfect match for the conditions encountered in process development. So how do they help and what is their impact?
1. Screening & Optimization: Reduce wet-lab experiments by using what is generally known about processes
Hybrid models marry the strengths of their two component parts. The machine-learning models learn from data that is too hard, or too specific to be incorporated within the fundamental models. Therefore, experiments only have to be carried out to understand the part that is described by the machine-learning tool.
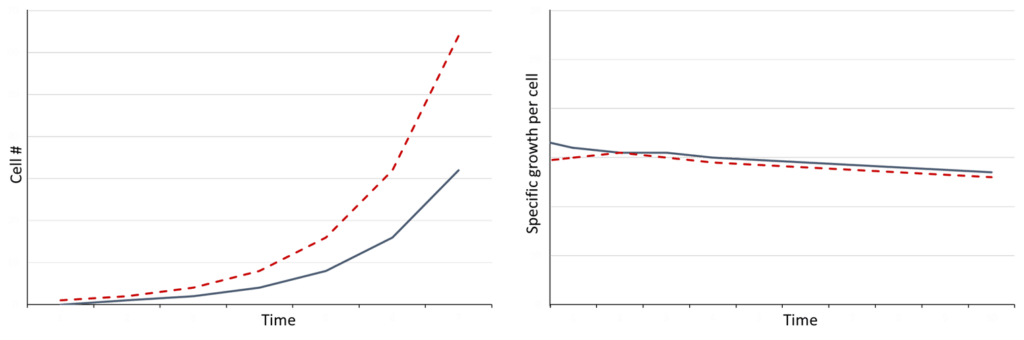
For instance, in an upstream perfusion process, bleeding, perfusion and feed rates need to be balanced to keep, for example, cell density constant over time. These rates are contained in the material balances. Having learned the specific growth rates, the feeding, bleeding, and perfusion rates can be changed in ways not tested before, and understood with the machine-learning models, without impacting the validity of the model in most cases. This integrated approach greatly reduces the number of experiments needed during process screening and optimization studies.
Figure 1: Changes in cell concentration in comparison to growth rate
2. Optimization & Characterization: Reduce wet-lab experiments by performing them insilico instead
Due to the fundamental element of their composition, hybrid models deliver increased prediction power and prediction accuracy, meaning they are able to make more accurate predictions for process scenarios not seen previously.
As such, before carrying out wet lab experiments the process conditions can be tested using the model. In the case where the hybrid model’s prediction can be trusted (small prediction interval), wet-lab experimentation may not be necessary. Where the prediction interval is rather large, an additional experiment will help the model learn from the scenario and allow for greater prediction accuracy thereafter.
Figure 2: Change in growth with an increase in temperature
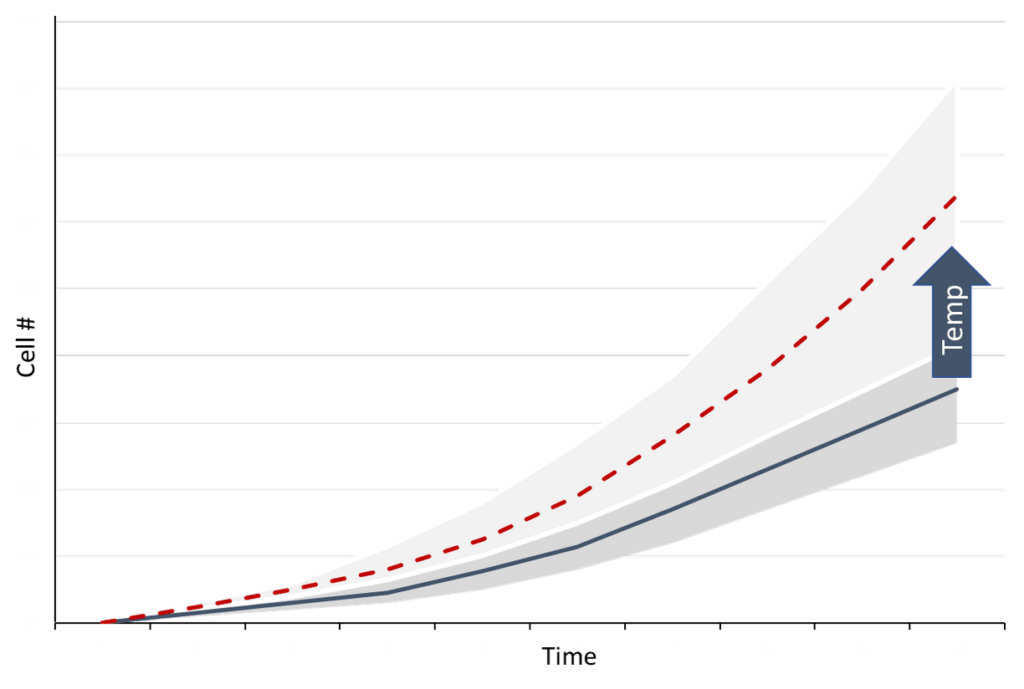
In cases where the model is dynamic, meaning it provides a prediction of the evolution of the experiment, decisions related to timing (when to induce, harvest, feed, etc) can be studied in detail with the model without losing prediction confidence. We have seen that by using our hybrid models for insilico experimentation during process optimization and characterization studies, the number of wet-lab experiments can be greatly reduced.
3. Scale up: Reduce wet-lab experiments for scale-up studies
The fundamental part of the hybrid model is typically posed in a way that it is scale independent. Transforming the variables used in the machine-learning component, by feature engineering so that they become scale-independent too, the hybrid model can be used to predict across scales. While predictions using a model trained on data from one scale yet directly applied on a different scale might be fairly inaccurate, by simply adding a few runs at this new scale you are able to significantly improve the prediction power of the model.
Figure 3: Hybrid-model supported scale up- learning the differences at larger scales through model adaptation
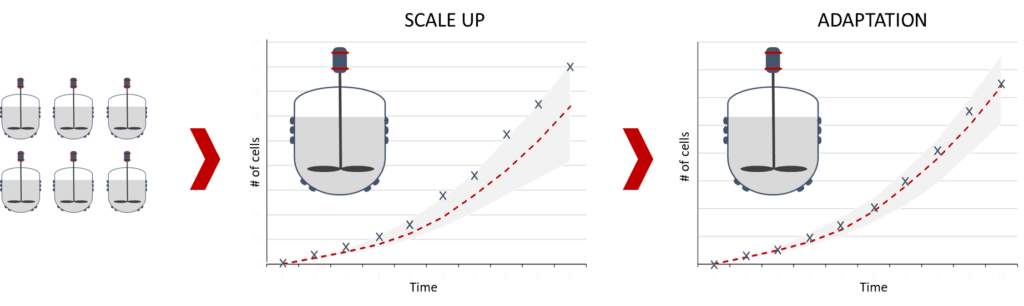
This is particularly useful to set, for example, feed, bleeding, or perfusion rates during the scale-up and adapt the process parameters to the slightly changed behavior at larger or smaller scale. The impact of the resulting reduction in experiments is significant when considering the cost of each experiment during this phase.
So, what is the full impact of hybrid models across process development?
Hybrid models therefore offer benefits and efficiencies across screening, optimization, characterization, and scale up. If we accumulate the impact across the entire scope of process development, by how much can we reduce experimentation?
In short, a lot. While not every operation is the same, the implementations we have performed across big pharma and CDMO’s in real-world use cases and operations have achieved efficiencies between 30-60% from the first project. The dramatic efficiencies are attributed to the strength of the hybrid models themselves as well as the integrated approach used. Compared to the norm in most operations of siloing experimentation and statistics, we pursue an integrated approach where the process and the model evolve together using bioprocess specific software.
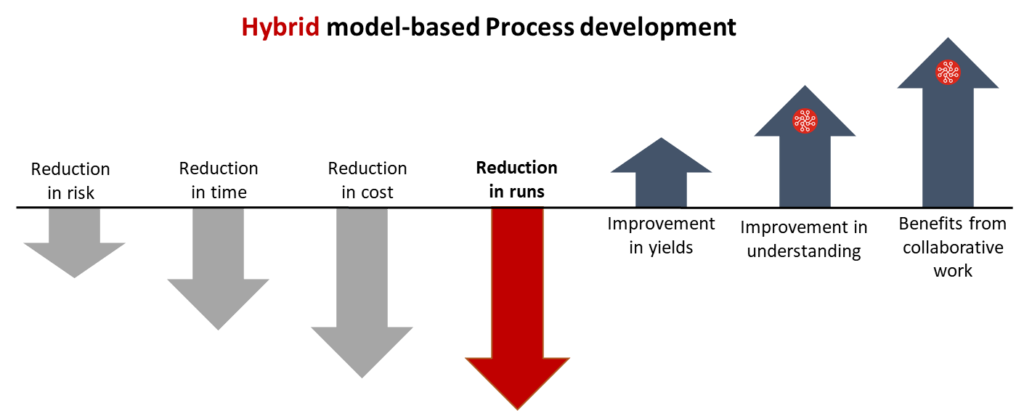
The efficiency impacts are self-evident. Operational cost and time savings are the most obvious benefits. However, when you consider the time savings within the context of a CDMO, the use of hybrid models become a driver of revenue growth as the organization is able to deliver more projects over the same time period. The use of hybrid models within an integrated approach also has organizational impact, breaking silo’s and building bridges between teams developing the process and those performing analysis.
If, like many in pharma, digitalization is high on your agenda, hybrid models are certainly a key element to add to the list.