The Path to Bioprocess Intelligence
Data is often called the new oil and has become the currency of innovation in many a boardroom. In bioprocessing, digitalisation initiatives are accelerating, driven by a desire for smarter, faster, and more resilient development and manufacturing operations. And while the industry has made significant progress in generating high volumes of process data through improved sensor technologies, PAT tools and high-throughput screening systems, a familiar challenge remains: collecting data is not the same as extracting value. Like unrefined oil, raw data alone cannot power better decisions. True impact comes from transforming that data into meaningful process intelligence that guide action.
The DIKW pyramid—Data, Information, Knowledge, Wisdom—is a widely used model to chart the path from raw data to actionable insight. It’s also a useful lens to assess how far biopharma has come in extracting value from its bioprocessing data. If Pharma 4.0 is to be more than a vision statement, we need to ask what is holding us back and preventing us from realising the promised value from this core data set.
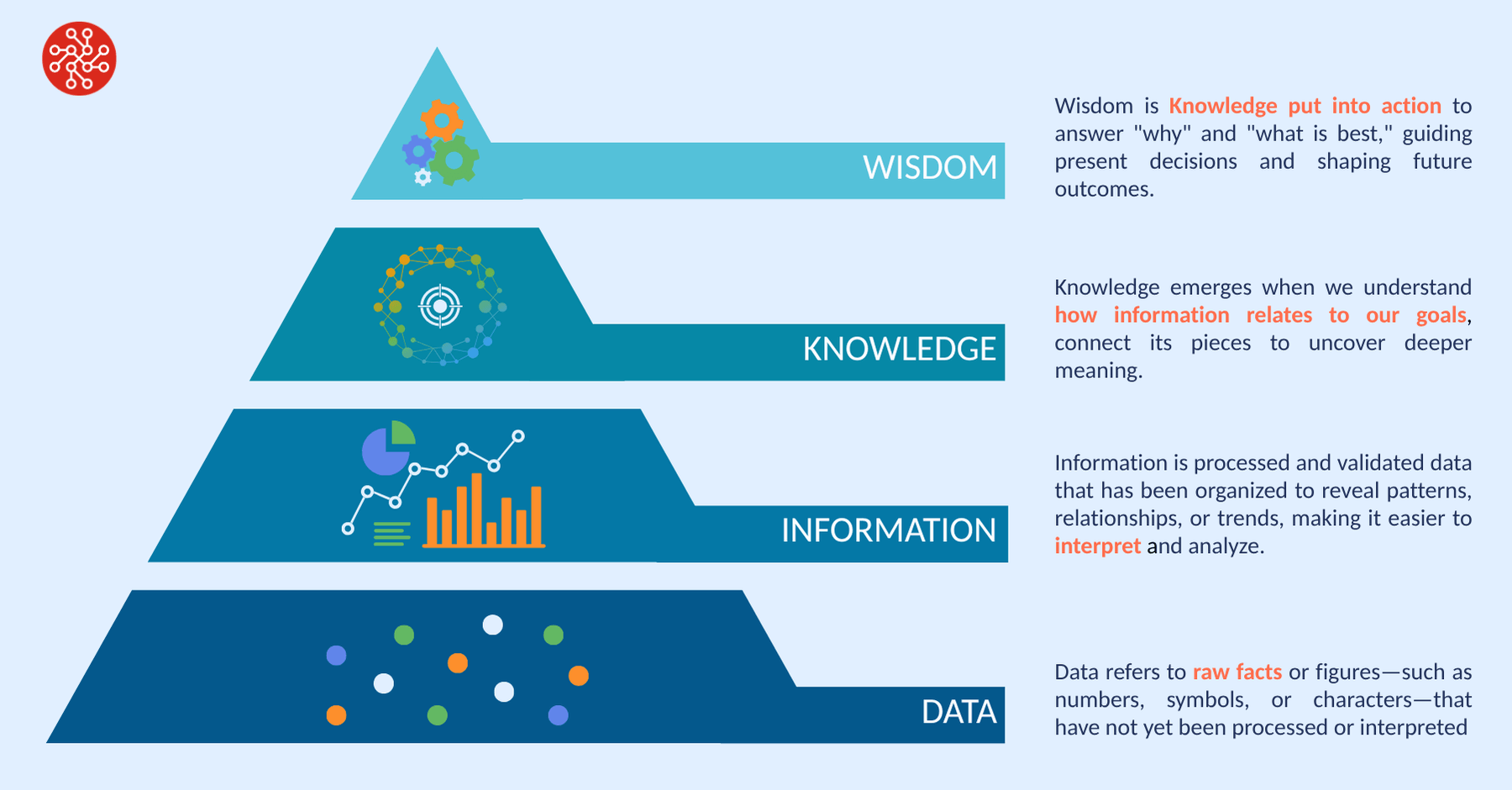
Data to Information: A Solid Start, But Not the Finish Line
The transition from data to information is one of the more mature aspects of digitalisation in bioprocessing. With the widespread deployment of sensors, soft sensors, and automated lab instruments, organisations routinely generate large volumes of time-series data, tracking variables such as pH, dissolved oxygen, viable cell density, and titer. Data historians, electronic lab notebooks (ELNs), and laboratory information management systems (LIMS) have become standard for structuring and storing this data. While challenges remain, particularly around data quality, completeness, and the availability of contextual metadata, the foundational ability to transform raw process signals into organised information is relatively well established.
Complementing this are data analytics and visualisation tools that allow teams to explore trends. Together, these tools enable scientists and engineers to more easily navigate complex datasets and extract meaningful patterns. However, while visualisation can surface correlations, it rarely provides deep insight into why those patterns occur—highlighting the need for more advanced approaches.
From Information to Knowledge: Where Bioprocessing Still Struggles
The transition from information to knowledge marks the shift from simply observing what happened to understanding why it happened. Knowledge implies a deeper comprehension of the underlying mechanisms and relationships that govern system behaviour—enabling teams to explain outcomes, anticipate risks, and make better-informed decisions. Knowledge in bioprocessing refers to a deep understanding of how critical process parameters and biological responses interact—such as how changes in variables like feed rate, temperature, or pH affect cell growth, metabolite production, and product quality. This knowledge enables scientists to design and optimize processes more effectively, ensuring consistent performance and reducing the risk of failure.
This is where bioprocess development continues to face real challenges. The generation of trusted, robust knowledge in this domain requires a deep understanding of a system which is complex, behaves non-linearly and is dynamic. This is beyond the scope of human interpretation, and where data modeling plays a critical role. However, the models most used in biologics, multiple linear regression (MLR), often fall short. MLRs assume linear relationships, fixed interactions, and independence between variables – assumptions that rarely hold in living systems where feedback loops, time dependencies, and variability are the norm.
As a result, MLRs tend to produce localised insights that may describe a specific dataset well but fail to hold outside that narrow operating space. In this way, MLRs often provide a false sense of confidence: they fit known data but struggle to extrapolate, explain variability, or support deeper knowledge creation. To move beyond local fits and toward generalisable process knowledge, more advanced modeling approaches, particularly those that account for nonlinearity and complex process dynamics, are needed.
Gen AI in Bioprocessing – Solving and Creating New Problems
To bridge this gap, new modeling approaches are emerging. Generative AI holds promise in enabling pattern recognition across large, complex datasets, particularly for knowledge extraction. However, its application in regulated, mechanistically driven environments like bioprocessing is a challenge. GenAI, especially LLMs (large language models) or deep neural networks, are unable to provide clear, interpretable reasoning for their outputs, leading to limited transparency.
Gen AI can also sometimes “hallucinate”- producing plausible but false outputs, especially when operating outside of well-understood training data. In bioprocessing, such errors could lead to incorrect process recommendations, misinterpretation of results, or poor design decisions. This is therefore far from being an approach that scientists or regulators would feel comfortable with, and far from a system to hand over operational control within the visionary context of lights-out-manufacturing. Gen AI is also data-hungry—it requires vast, diverse datasets to train effectively and generate reliable outputs. This makes them ill-suited for bioprocess development, where data availability is inherently limited. Then there is the question of IP. Gen AI tools may expose sensitive process data as they use a large pool of data to generate outputs. What is clear is that a strong degree of human oversight is still needed for these to be used in practice.
Our Scientific Knowledge is Good, but not Good Enough
On the other end of the spectrum are mechanistic models, which are mathematical representations of a system based on first principles knowledge, such as mass balances, reaction kinetics, etc. As they lean on known phenomena, results are extremely interpretable as opposed to being a black box. For similar reasons, they can be used to extrapolate and simulate towards unknown scenarios. Indeed, their transparency makes them a regulator’s dream.
Their major drawback is that they are too rigid for the complex, non-linear, and dynamic domain of bioprocessing. They struggle to accurately describe process-specific or biological behaviour that is not well understood. While better suited to certain process operations like chromatography, where dynamics are more completely described, they are not reliable for upstream processing. While mechanistic models are powerful tools, they can’t capture everything. Their accuracy is limited to what is already known and explicitly defined—leaving blind spots where biological behavior is poorly understood or too complex to model precisely. If the goal of Pharma 4.0 is an automated, self-regulating system which is informed by model-generated knowledge and insight, blind spots are a no go.
The Best of Both Worlds
Hybrid models represent the most effective approach for generating trusted, accurate process knowledge, as they are uniquely well-suited to the complex and regulated environment of biologics development and manufacturing, offering both interpretability and flexibility. Their hybrid structure incorporates many of the benefits while disregarding many of the drawbacks of the other modelling approaches when considering the biological, operational and regulatory aspects of bioprocessing.
Hybrid models include a mechanistic backbone that incorporates established scientific principles—such as mass balances and kinetic models. This foundation enables reliable extrapolation across scales and under novel conditions. Because these models are grounded in physical laws, they eliminate the risk of AI “hallucinations” and significantly reduce the likelihood of generating misleading outputs.
Importantly, as they lean on this mechanistic core vs. extensive databases, they pose less of an IP risk. IP-conscious providers, such as DataHow, have developed hybrid models where the machine-learning component is applied only to a company’s specific, internally generated process data. These trained models then form part of the proprietary knowledge linked to a process, owned by the organisation.
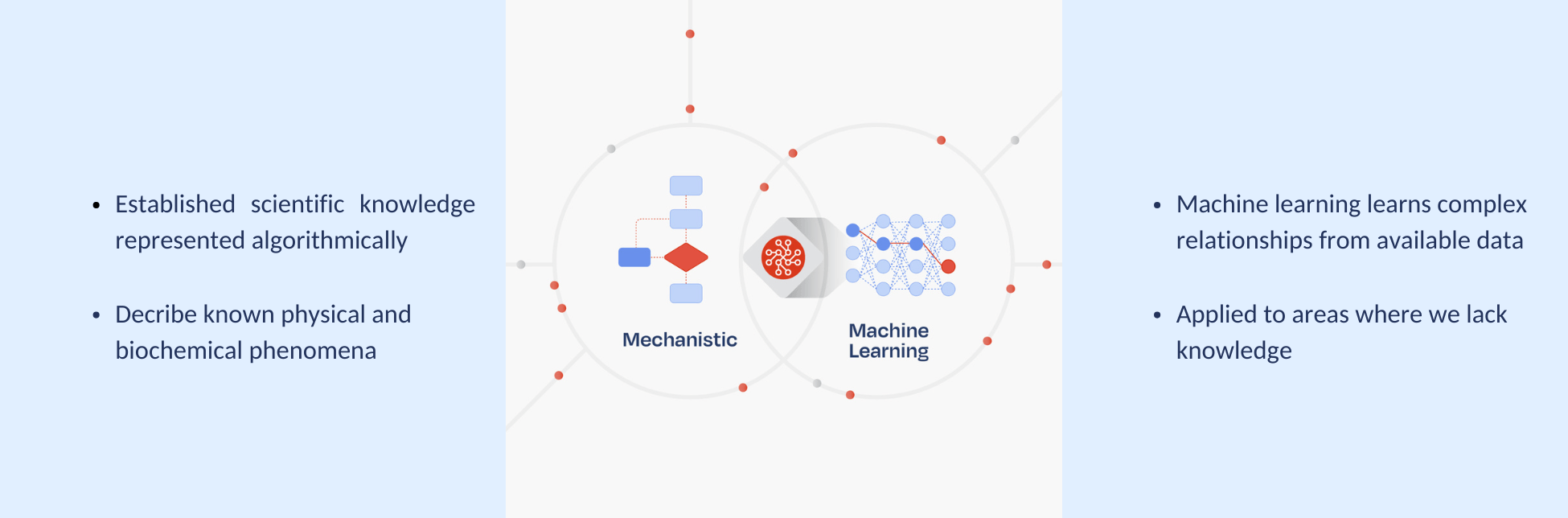
This mechanistic core is complemented by a flexible data-driven, machine learning component, which learns process-specific behaviors from available data, providing high-definition insight and process knowledge. It also does it efficiently. While purely machine learning–based models often demand large datasets to perform reliably, hybrid models shift the paradigm. By including a mechanistic core, hybrid models constrain the solution space to only scientifically plausible regions. This focused scope enables the machine learning component to operate within a narrower, more meaningful domain—requiring significantly less data to generate accurate and robust process knowledge.
When each experiment comes at a significant cost, hybrid models combined with optimal design strategies offer exceptional value—maximizing the knowledge gained from every data point. This modeling approach is proven to outperform MLR models generally used by the industry, allowing development teams to reduce experimental effort while increasing process insight and knowledge. In the pursuit of high-resolution, economically efficient process knowledge, hybrid modeling is becoming the gold standard for bioprocessing.
The path to dynamic process intelligence
While knowledge describes what influences a process and why, wisdom or intelligence is about using that knowledge to guide actions, optimise outcomes, and adapt to change. Wisdom represents the ability to choose the best course of action—applying knowledge proactively to support optimal, informed decision-making. If knowledge is knowing how cells grow at a given temperature, intelligence is understanding how changes in temperature will affect that growth—and determining what actions to take to return the process to optimal conditions.
This capability presents a significant opportunity for scientists, engineers, and operators—but it also introduces potential risks. Relying on technology to support high-stakes decisions in sensitive bioprocessing environments demands that the system is both fit for purpose and entirely robust. This technology must embody a deep, comprehensive understanding of the bioprocess and apply that knowledge dynamically. It must adhere to scientific rigor while accommodating unknown or complex biological behaviors. It must explain why effects occur—not just at the endpoint, but throughout the entire process. It must be capable of extrapolating and predicting future behaviour, adapting seamlessly across scales, while doing so efficiently within actionable timeframes. For these reasons, hybrid models are the gateway to trusted, operationalised process intelligence.
When integrated correctly, the hybrid model becomes a central process insight engine, which can be queried and used across multiple use cases:
Optimal Experimental Design: move from exploratory trial-and-error to targeted, knowledge-driven experimentation
When coupled with Bayesian optimization, hybrid models can recommend what experiments to run next to maximize learning, based on what is already known.
In silico Experimentation: simulate experiments vs. Wet lab
Simulate how a process is likely to behave under different conditions—even before an experiment is run. Only run experiments when needed.
Root cause analysis (RCA): understand why deviations or errors occurred
Hybrid models offer a powerful advantage by not only identifying what went wrong but also uncovering why it happened and when during the process the issue began to emerge.
Scenario simulation: determine what would happen if?
Hybrid models allow teams to anticipate deviations, explore “what-if” scenarios, and make informed decisions before issues occur. If an error has occurred, hybrid models can recommend and simulate remediation strategies to bring a process back on target.
Predictive forecasting: forecast process performance in real-time
When hybrid models are coupled with real-time process data, they can continuously forecast the process. This allows operators to detect early signs of drift or deviation and take proactive steps to steer it back on course.
Predictive control: forecast and optimise in real time
Taken a step further, hybrid models can forecast future process behaviour in real time and recommend optimal adjustments to keep the process within target ranges.
For hybrid modeling to deliver meaningful impact in these use cases, it must be embedded within practical, user-friendly applications that make its intelligence accessible and actionable for scientists, engineers, and operators. These tools must also integrate seamlessly into the broader digital and operational ecosystem—connected to essential data streams, ingesting both online and offline data, and enabling either direct intervention (closed-loop control) or decision support (human-in-the-loop).
Generating ROI on early-stage digital investments
To generate real return on the industry’s early digital investments, companies must go beyond data collection and commit to unlocking the full value of their data. Without this, digitalisation efforts risk becoming sunk costs—tools in place, but insight unrealised. Modeling technologies are the critical enabler for this next step, providing the bridge from raw data to actionable intelligence. Yet in the complex, nonlinear, and regulated world of bioprocessing, hybrid models stand out as the most practical and powerful solution, offering a unique combination of scientific grounding and data-driven flexibility.
The technology itself is also mature and readily accessible. Companies like DataHow have been at the forefront of hybrid modeling for over a decade, developing bioprocess-specific solutions that go far beyond raw algorithmic tools. With its intuitive, process scientist-oriented interface, DataHowLab makes advanced hybrid modeling practical and actionable, enabling users to tackle key development and manufacturing tasks without needing to know the dark arts of data science. The softwares applications provide a seamless path from data to process intelligence.
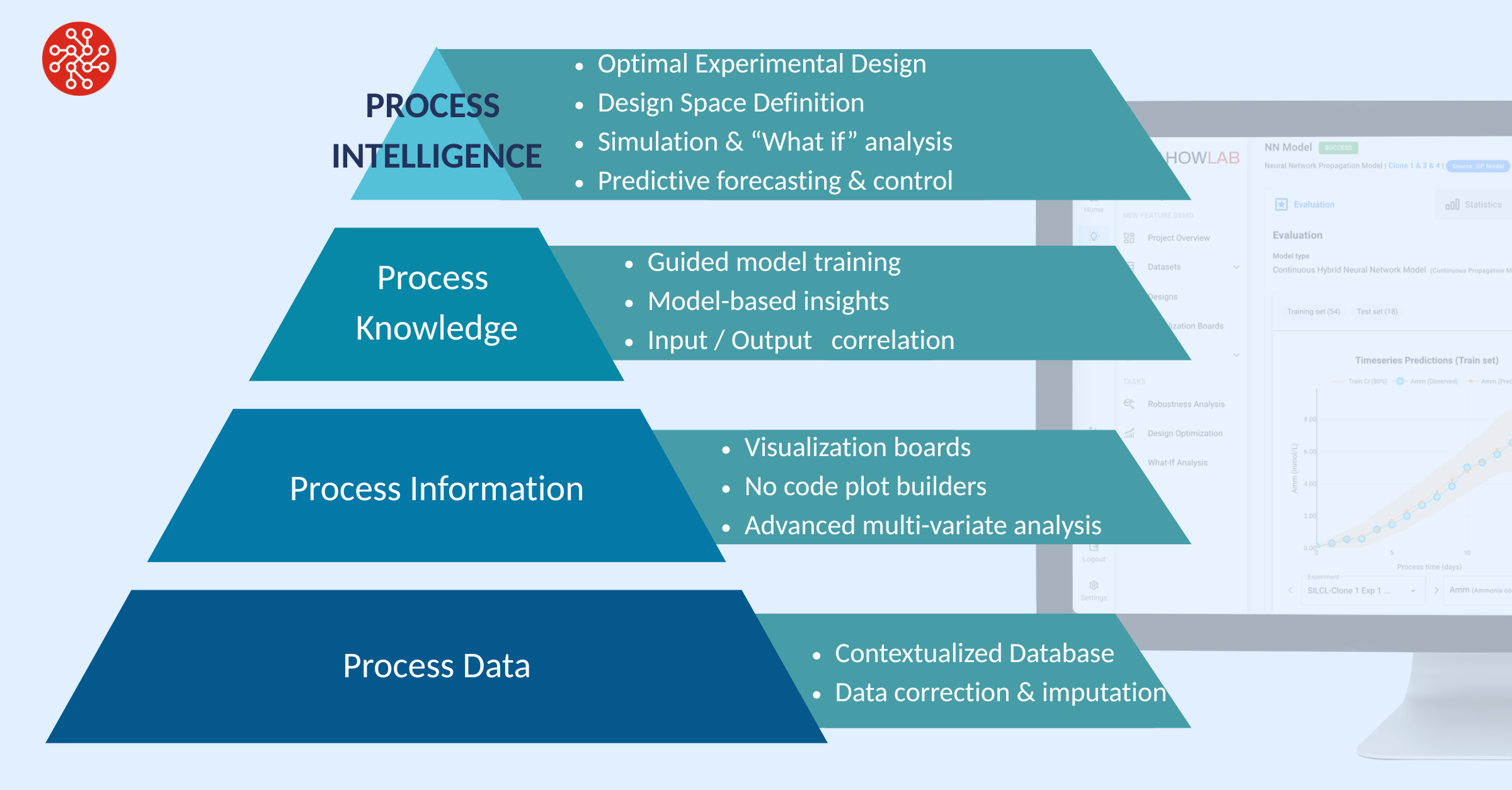
The promise of this technology is not a visionary science future as it’s being implemented and generating value across the process lifecycle already. The technology and software are currently being used across many of the world’s leading biopharmaceutical organisations. Process development scientists are realising significant gains in R&D through reduced experimental workloads and faster, more efficient paths to process understanding. The ability to minimize large-scale runs alone yields savings of hundreds of thousands of dollars and shortens timelines by weeks. The impact in manufacturing is even greater, as the technology can help reduce run failures and enable continuous process optimization—boosting productivity, improving margins, and increasing the volume of product reaching the market. As more companies seek to capitalise on their digital infrastructure, solutions like DataHowLab demonstrate how hybrid modeling can turn data into a true driver of value across the process lifecycle.